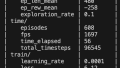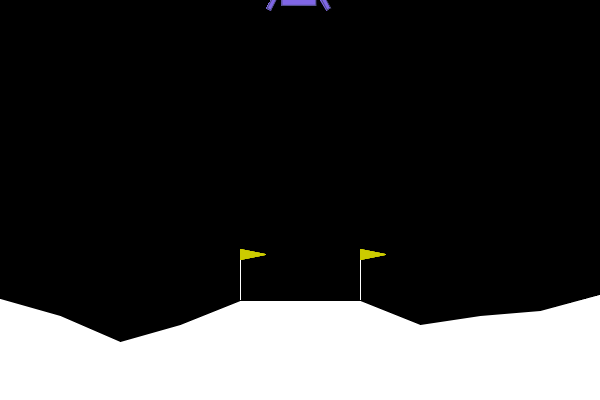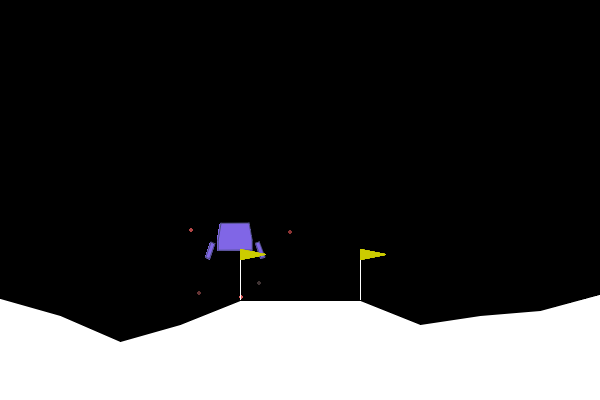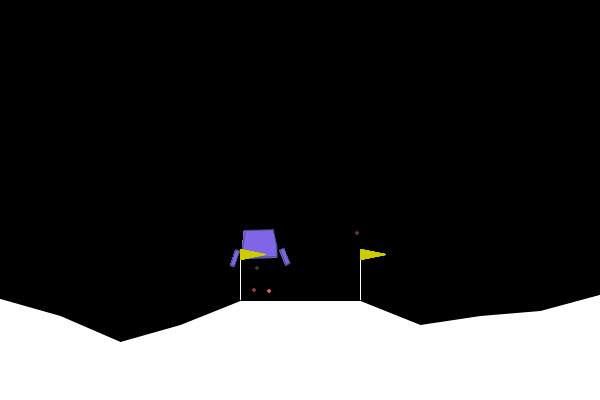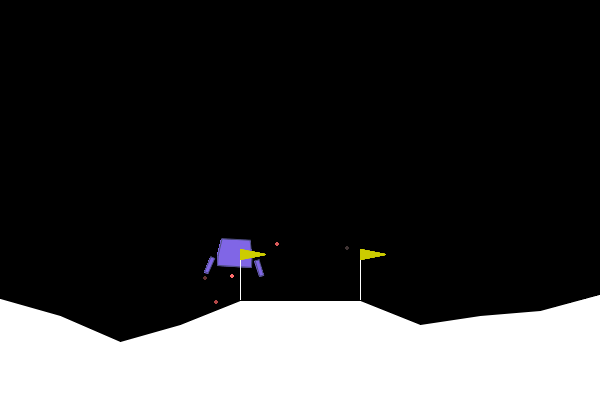
LunarLanderのサンプル.
学習step 2e6(2,000,000)回レベルだと着陸までいかない・・・?

Examples — Stable Baselines3 2.5.0a0 documentation
stable-baselines3.readthedocs.io
import gymnasium as gym
from stable_baselines3 import DQN
from stable_baselines3.common.evaluation import evaluate_policy
# Create environment
env = gym.make("LunarLander-v2", render_mode="rgb_array")
# Instantiate the agent
model = DQN("MlpPolicy", env, verbose=1)
# Train the agent and display a progress bar
model.learn(total_timesteps=int(2e6), progress_bar=True)
# Save the agent
model.save("dqn_lunar")
del model # delete trained model to demonstrate loading
# Load the trained agent
# NOTE: if you have loading issue, you can pass `print_system_info=True`
# to compare the system on which the model was trained vs the current one
# model = DQN.load("dqn_lunar", env=env, print_system_info=True)
model = DQN.load("dqn_lunar", env=env)
# Evaluate the agent
# NOTE: If you use wrappers with your environment that modify rewards,
# this will be reflected here. To evaluate with original rewards,
# wrap environment in a "Monitor" wrapper before other wrappers.
mean_reward, std_reward = evaluate_policy(model, model.get_env(), n_eval_episodes=10)
# Enjoy trained agent
vec_env = model.get_env()
obs = vec_env.reset()
#for i in range(1000):
while True:
action, _states = model.predict(obs, deterministic=True)
obs, rewards, dones, info = vec_env.step(action)
vec_env.render("human")
if dones:
print("done")
break
追記
学習を2,000万回にしたら着陸できた!