2023/11時点,gymのメンテは中止とのこと.
後継のgymnasiumを利用した方が良さそう.

Gymnasium Documentation
A standard API for reinforcement learning and a diverse set of reference environments (formerly Gym)
gymnasium.farama.org
#https://stable-baselines3.readthedocs.io/en/master/guide/quickstart.html#getting-started
import imageio
import numpy as np
import gymnasium as gym
from stable_baselines3 import A2C
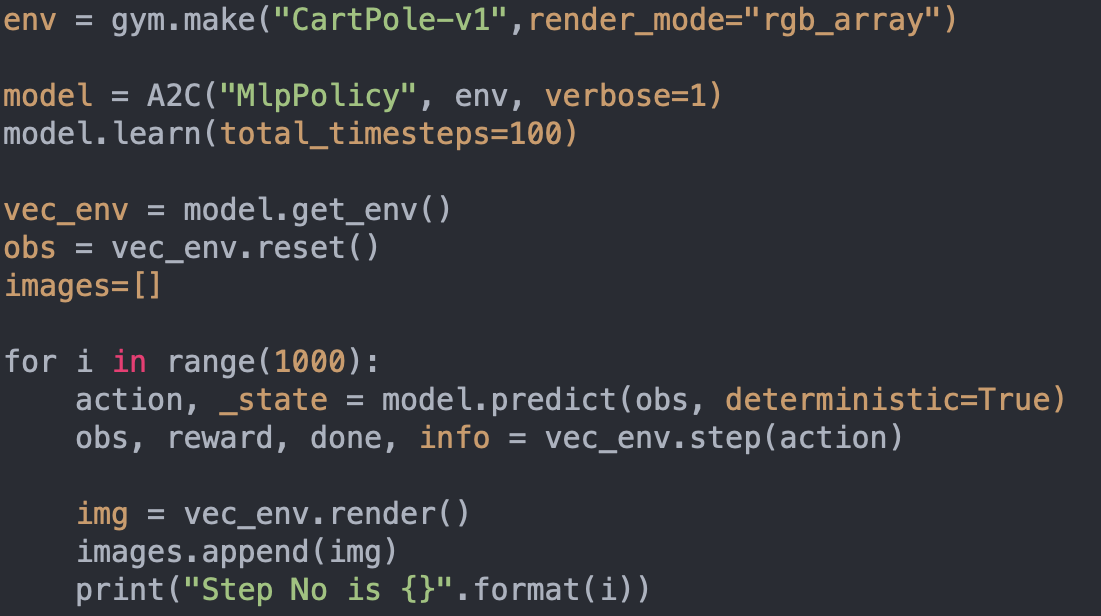
env = gym.make("CartPole-v1",render_mode="rgb_array")
model = A2C("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=100)
vec_env = model.get_env()
obs = vec_env.reset()
images=[]
for i in range(1000):
action, _state = model.predict(obs, deterministic=True)
obs, reward, done, info = vec_env.step(action)
img = vec_env.render()
images.append(img)
print("Step No is {}".format(i))
#1エピソードで終わる場合
#if done:
# print('done')
# break
imageio.mimsave("CartPole-v1.gif", [np.array(img) for i, img in enumerate(images) if i%2 == 0], fps=29)
env = gym.make("CartPole-v1", render_mode="rgb_array")render_mode
描画モード
- human:人が確認可能な形で描画してくれる.
- rgb_array:np.array型,shapeは(x,y,3)として返り値を渡す.都度1フレームとして保存し,後程gifに変換する場合に使うイメージ.
- その他
- ansi
- rgb_array_list
- ansi_list
model = A2C("MlpPolicy", env, verbose=1)verbose
学習時にログを出すか否か
- 0:出力なし
- 1:出力あり
- 2:デバッグ用出力
model.learn(total_timesteps=100)total_timesteps
学習ステップ