公式から拝借.
コード内に記載がありますが,私の環境(MacBook Air Apple M1 Sonoma 14.1.1)では以下を事前に実施しないとエラーとなった.
HomeBrewが入っていない方はインストールした後,以下を実施してください.
(apt-getをbrewに変更する)
#!apt-get update && apt-get install swig cmake
#!pip install box2d-py
#!pip install "stable-baselines3[extra]>=2.0.0a4"# -*- coding: utf-8 -*-
"""saving_loading_dqn.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/github/Stable-Baselines-Team/rl-colab-notebooks/blob/sb3/saving_loading_dqn.ipynb
# Stable Baselines3 - Training, Saving and Loading
Github Repo: [https://github.com/DLR-RM/stable-baselines3](https://github.com/DLR-RM/stable-baselines3)
[RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo) is a training framework for Reinforcement Learning (RL), using Stable Baselines3.
It provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.
Documentation is available online: [https://stable-baselines3.readthedocs.io/](https://stable-baselines3.readthedocs.io/)
## Install Dependencies and Stable Baselines Using Pip
```
pip install stable-baselines3[extra]
```
"""
# for autoformatting
# %load_ext jupyter_black
#!apt-get update && apt-get install swig cmake
#!pip install box2d-py
#!pip install "stable-baselines3[extra]>=2.0.0a4"
"""## Import policy, RL agent, ..."""
import gymnasium as gym
import numpy as np
from stable_baselines3 import DQN
"""## Create the Gym env and instantiate the agent
For this example, we will use Lunar Lander environment.
"Landing outside landing pad is possible. Fuel is infinite, so an agent can learn to fly and then land on its first attempt. Four discrete actions available: do nothing, fire left orientation engine, fire main engine, fire right orientation engine. "
Lunar Lander environment: [https://gymnasium.farama.org/environments/box2d/lunar_lander/](https://gymnasium.farama.org/environments/box2d/lunar_lander/)

We chose the MlpPolicy because input of Lunar Lander is a feature vector, not images.
The type of action to use (discrete/continuous) will be automatically deduced from the environment action space
"""
model = DQN(
"MlpPolicy",
"LunarLander-v2",
verbose=1,
exploration_final_eps=0.1,
target_update_interval=250,
)
"""We load a helper function to evaluate the agent:"""
from stable_baselines3.common.evaluation import evaluate_policy
"""Let's evaluate the un-trained agent, this should be a random agent."""
# Separate env for evaluation
eval_env = gym.make("LunarLander-v2")
# Random Agent, before training
mean_reward, std_reward = evaluate_policy(
model,
eval_env,
n_eval_episodes=10,
deterministic=True,
)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
"""## Train the agent and save it
Warning: this may take a while
"""
# Train the agent
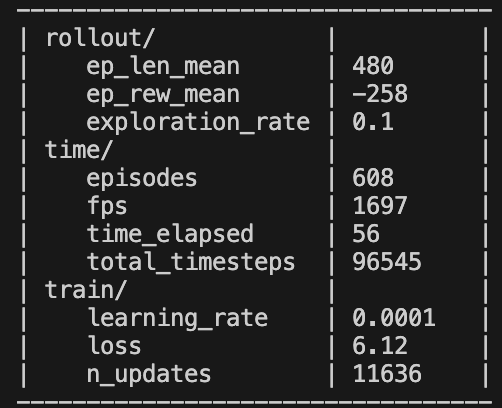
model.learn(total_timesteps=int(1e5))
# Save the agent
model.save("dqn_lunar")
del model # delete trained model to demonstrate loading
"""## Load the trained agent"""
model = DQN.load("dqn_lunar")
# Evaluate the trained agent
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")